Nathan S. de Lara
Learning and Searching hoping to find algorithms that do that too

Hi, I’m Nathan, an incoming PhD student at Carnegie Mellon University hoping to work on off-policy learning. At the moment I’m spending the summer interning at Mistral in San Francisco on the Pre-Training team.
Previously, I did my Master of Science (MSc) at the University of Toronto in the Robot Vision and Learning Lab Supervised by Prof. Florian Shkurti. Before that, I spent 4 great years at McGill University where I was fortunate to work with Prof. Doina Precup and Prof. Russell Steele.
My main driving question during my research: How can RL scale better than BC for Pre-Training?
Recent works suggest RL should outperform BC when trained on large noisy datasets containing suboptimal demonstrations. This setting bears a strong resemblance to the majority of internet data out there. Yet, RL has failed to be used in favour of BC for large-scale pre-training. My research goal is to help get RL to a place where it reliably surpasses BC.
News
| Jul 04, 2026 | Our paper SMAC: Score-Matched Actor-Critics for Robust Offline-to-Online Transfer was accepted to ICML 2026! 🎊 |
|---|---|
| Sep 17, 2025 | Our paper STITCH-OPE: Trajectory Stitching with Guided Diffusion for Off-Policy Evaluation was accepted to NeurIPS 2025 as a spotlight! 🎉 |
| Sep 01, 2024 | Started my Masters of Science at the University of Toronto with Prof. Florian Shkurti |
| Aug 05, 2024 | Presented work on the representation collapse experience by recurrent networks when applied Continual Reinforcement Learning at the Can’t Believe It’s Not Better Workshop: Failure Modes of Sequential Decision-Making in Practice hosted at RLC |
| Apr 15, 2024 | Graduated from McGill University with a Bachelor of Arts in the Honours Mathematics and Computer Science Program! |
Selected Publications
-
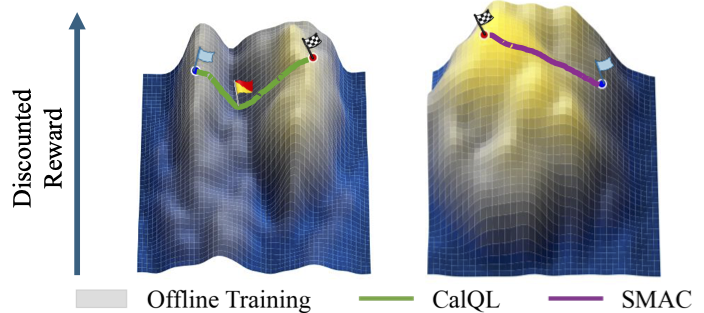 SMAC: Score-Matched Actor-Critics for Robust Offline-to-Online Transfer2026
SMAC: Score-Matched Actor-Critics for Robust Offline-to-Online Transfer2026 -
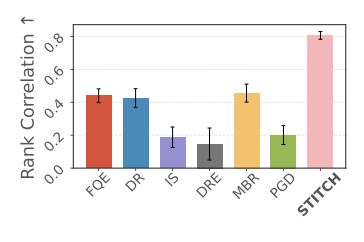 STITCH-OPE: Trajectory Stitching with Guided Diffusion for Off-Policy Evaluation2025
STITCH-OPE: Trajectory Stitching with Guided Diffusion for Off-Policy Evaluation2025 -
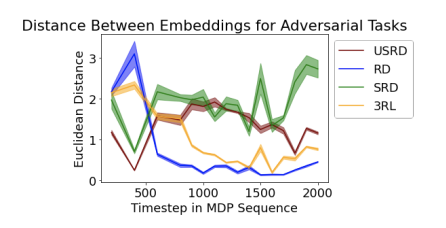 Recurrent Policies Are Not Enough for Continual Reinforcement LearningIn I Can’t Believe It’s Not Better Workshop: Failure Modes of Sequential Decision-Making in Practice (RLC 2024), 2024
Recurrent Policies Are Not Enough for Continual Reinforcement LearningIn I Can’t Believe It’s Not Better Workshop: Failure Modes of Sequential Decision-Making in Practice (RLC 2024), 2024 -
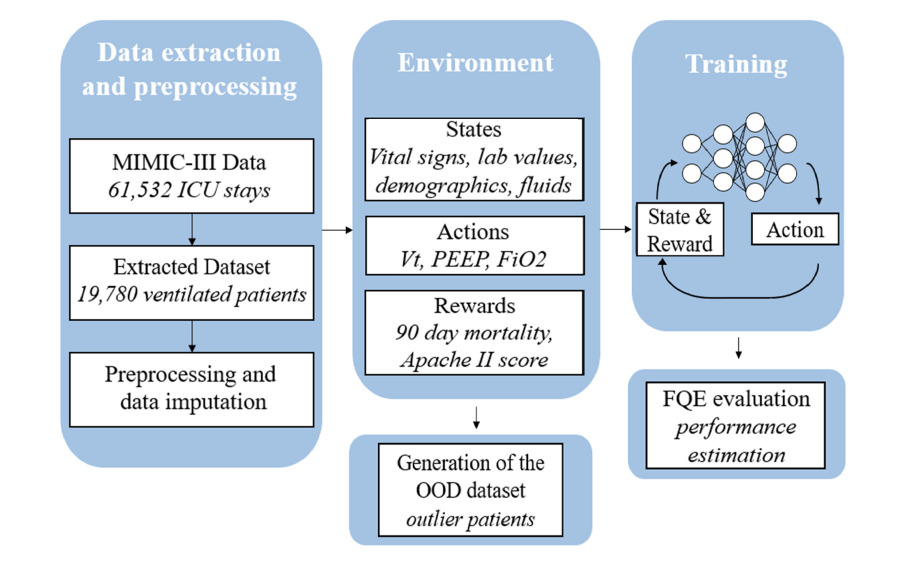 Towards safe mechanical ventilation treatment using deep offline reinforcement learningIn Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, 2023
Towards safe mechanical ventilation treatment using deep offline reinforcement learningIn Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, 2023